

When the Cloud Wobbles: BCP, Failover, and Degraded Modes in CCaaS
What customers really mean when they ask about redundancy is simple: when something breaks, can people still reach us, can agents still work, and can we still defend what happened later?
Most BCP conversations in CCaaS are wrong. They start with redundancy diagrams and region failover stories. But that is not what actually breaks first. Real incidents rarely look like clean outages. They begin as wobble. Latency spikes, DNS timeouts, API throttling, and partial failures that make the system unpredictable before it ever goes down.
More importantly, not everything that breaks matters equally. Some failures are visible but survivable. Others strand your operation. Agents might not be able to log in, dashboards may stop updating, admin actions may fail. That is painful, but customers can still reach you and conversations can continue. When routing or reachability fails, your customers cannot reach you. That is when it stops being an IT issue and becomes a business problem.
So the real question is not "do you have DR?" It is whether the system can keep the critical path alive while everything else is unstable.
The wobble vs. the crash (plan for turbulence, not just total outage)
Most architectures are designed for failure. Very few are designed for instability.
I often get asked about specific failure scenarios. What happens if an SBC fails? What if an availability zone goes down? What if an entire region is impacted? Those are the easy questions. The harder problem is when nothing is fully down, but everything is slightly broken.
The cloud rarely just "dies." It wobbles first. Latency spikes, DNS timeouts, and API errors appear before anything is fully down. This is where the distinction between critical and non-critical paths becomes real. The system is not gone, but parts of it are no longer reliable.
One of the clearest real-world write-ups of this pattern comes from Webex Contact Center engineering, where the focus is on staying steady through control-plane turbulence rather than planning only for a clean regional outage.
- The wobble: latency spikes, DNS timeouts, elevated error rates, and inconsistent system behavior
- The crash: a region or major dependency becomes unavailable
Most BCP narratives plan for the crash. Credible continuity plans are designed to survive the wobble first.
- If routing depends on last-minute scale-up actions and the control plane is struggling, the system becomes brittle.
- Static stability, with pre-provisioned headroom and controlled scaling, is what keeps the data plane working while the control plane is unstable.
In practice, this means keeping critical paths running on pre-provisioned capacity and avoiding reliance on real-time scaling during an incident.
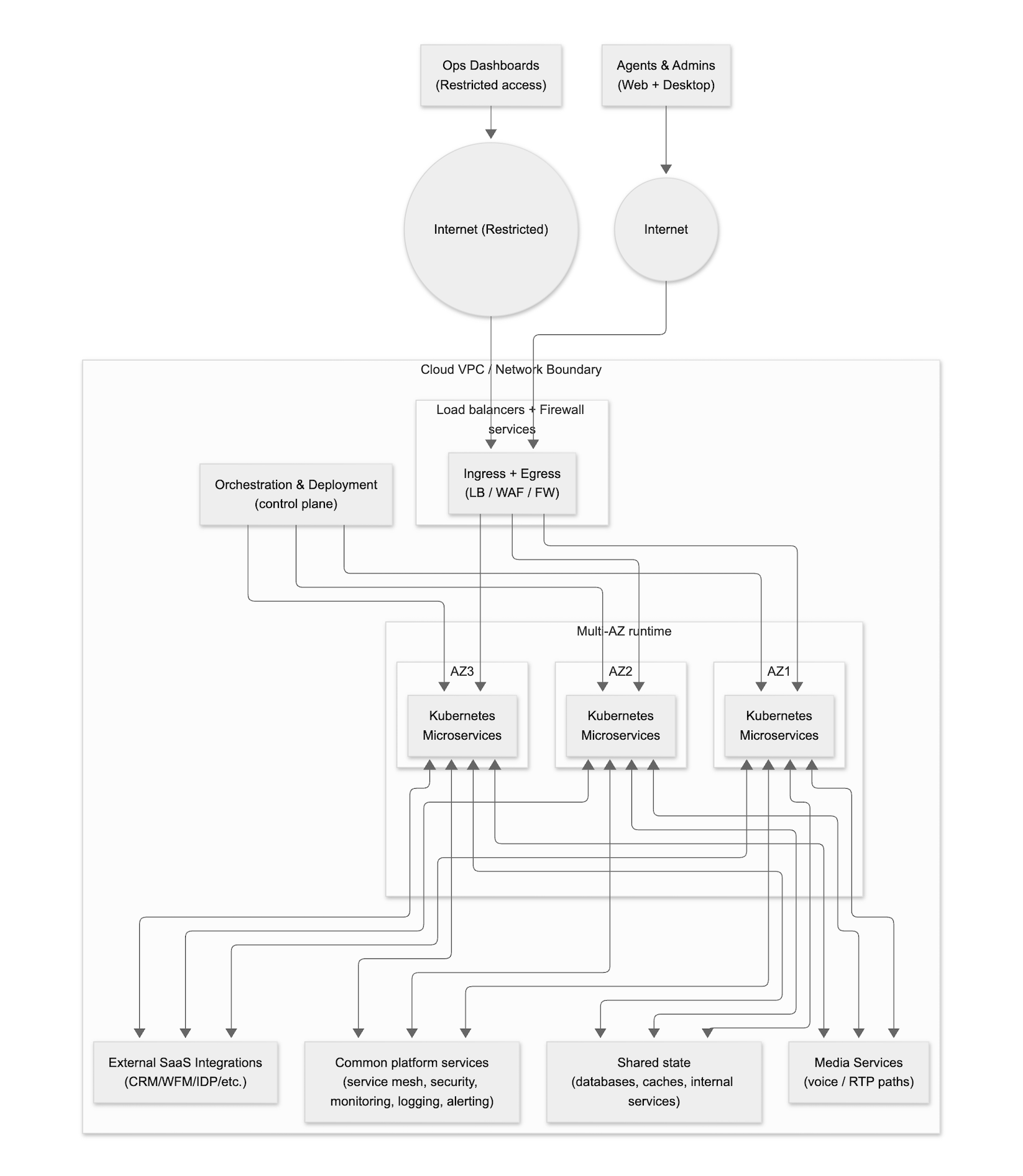
Start with what actually matters
When something goes wrong, customers do not think in terms of regions, zones, or redundancy. They care about what still works.
- Can customers still reach you?
- Can interactions still be handled?
- Are records still being captured?
- Can your team see what is happening and respond?
Everything else is secondary.
This is also where RTO and RPO become real. RTO (Recovery Time Objective) is not just how fast you recover. It is how long the business is impacted. RPO (Recovery Point Objective) is not just data loss. It is missing conversations, incomplete records, and potential compliance exposure.
A 15 minute gap is not just time. At scale, it can mean a significant number of missing recordings, transcripts, or audit events depending on call volume and capture design.
So the trade-off is explicit. You either design for tighter replication and durable capture, or you accept loss and define the impact.
But in practice, one question matters more than both. What still works when the system is not fully healthy.
This is where most designs fall apart. They assume clean failure. Real systems spend most of an incident in between.
A simple way to make this concrete is service tiering.
- Critical path: customer reachability and routing must continue
- Supporting functions: agent login, CRM integrations, and real time views may degrade
- Non-critical functions: reporting, configuration changes, and exports can wait
You might not be able to log in an agent or make an admin change for a period of time. But if customers can still reach you and conversations continue, the business is still operating.
What should the business actually look at
There is a reason most organisations moved from on-prem to CCaaS. Speed, cost, elasticity, and the ability to offload infrastructure complexity.
But that shift comes with trade-offs.
You are no longer designing every failure mode yourself. You are inheriting a platform with its own definitions of availability, recovery, and responsibility boundaries.
So the first question is not "is the platform resilient?" The first question is what does resilience mean for your business.
Because not everything needs to be protected equally.
- Is your priority that customers can always reach you, even if agents have limited functionality
- Is it that every interaction must be captured for compliance, even during degradation
- Is it that agents must always be able to log in and operate normally
You will not get all of these at the same level without trade-offs.
This is where many evaluations go wrong. They look at a single number like 99.99 and assume it reflects their business reality. It does not.
That number reflects platform availability as defined by the provider. It does not guarantee that every workflow, integration, or user action will work during an incident.
So the real work starts here. Define what must never fail, what can degrade, and what can wait. Once that is clear, architecture decisions, redundancy models, and failover strategies become much easier to reason about.
Redundancy is not the answer
Most redundancy conversations start with a simple idea. Duplicate everything and fail over when something breaks.
In a SaaS platform, much of that already exists. Infrastructure is distributed, services are replicated, and failures at the node or zone level are expected and handled.
But that does not guarantee continuity.
Redundancy gives you options. Failover determines whether those options actually work.
And that is where most designs fall apart.
Failover is not what people think it is
Most people imagine failover as a clean switch. One system goes down, another takes over, and everything continues.
That is not how it works in practice.
Failover is not about moving everything. It is about what moves first, and what does not move at all.
Traffic can usually be redirected quickly. New requests, new sessions, and new calls can be steered to a healthy path.
State is different.
In real-time systems like contact centers, conversations are not easily moved. A voice call is a pinned session. A live interaction is tied to a specific path. If that path fails, recovery is not about continuing the same session. It is about ensuring the next interaction succeeds.
This is why continuity is measured differently.
- Not "was every interaction preserved"
- But "can the next customer reach you"
This distinction is often missed.
During a failure:
- Some in-flight interactions may drop
- Some state may be reconstructed, not preserved
- Some data may arrive late or out of order
And all of this can still be considered a successful recovery if the critical path is restored quickly. This is also why statements like "sub-minute failover" need to be understood correctly. It does not mean every interaction continues uninterrupted. It means new interactions can be routed successfully within that time.
This is also where timing becomes real.
Failover is not just the act of switching. It includes:
- Detecting the problem
- Deciding to act
- Redirecting traffic
- Stabilising the system
The delay is often not in the switch itself, but in detection and safe execution.
And in larger failures, failover is not always automatic.
Triggering it too early or under partial failure can create a worse outcome. Systems may disagree on state. Dependencies may not be ready. Recovery paths may not be fully synchronised.
So failover becomes a controlled decision, not just a technical event.
Failover for voice is not the same as failover for web
This is where CCaaS architecture diverges from generic SaaS conversations. A web request can often be retried or replayed. A voice session cannot always be moved so cleanly. RTP streams, SIP signaling paths, SBC placement, and carrier behavior all shape what is realistically recoverable.
The most important truth to state plainly is this: in severe failure scenarios, some in-flight calls may still drop. That does not mean the platform lacks continuity. It means the continuity goal is usually centered on protecting ongoing sessions where possible while restoring new-call reachability very quickly.
That is why statements like "sub-minute failover" need context. In a CCaaS design, that often means the next inbound call is routed correctly through a healthy path, not that a damaged live conversation is magically teleported to another region.
Why DNS alone is often not enough
DNS can be part of the solution, but it is a blunt tool. Low TTL values do not guarantee low failover time because some resolvers and ISPs cache longer than expected. For tighter outcomes, architectures tend to rely on global steering methods such as GSLB, anycast-style approaches, or tightly controlled application gateways.
Data continuity is about trade-offs, not guarantees
One of the most common assurances you will hear is "your data is safe." That statement needs context.
That statement needs unpacking.
In a distributed system, data is constantly being written, replicated, and propagated across multiple locations. This is what keeps the system available during failures.
But it does not mean everything is perfectly in sync.
There is always a gap, even if it is small.
This is what RPO really represents. Not a number on paper, but a window where some data may not exist in the recovery path.
During an incident:
- Some interactions may not be fully captured
- Some records may appear late
- Some state may be reconstructed rather than preserved
And all of this is a function of how replication is designed.
This is also where backups are often misunderstood.
Backups protect you from bad data. They help you recover from corruption, accidental deletion, or a faulty release.
They do not guarantee continuity during a live failure.
Restoring from backup takes time, and in many cases, backups are not immediately usable in a different region without prior design.
So again, the trade-off is explicit.
You either invest in tighter replication and faster propagation, or you accept a defined window of data loss.
There is no design that gives you zero loss, zero latency, and infinite distance at the same time.
Your uptime is bounded by what you don't control
Even if your platform is perfectly designed, your system is only as reliable as the dependencies it relies on.
And those dependencies fail differently.
They rarely go down cleanly. They slow down, return inconsistent responses, or behave unpredictably under load.
This is where many systems break.
Not because a dependency is down, but because it is partially failing.
- Identity providers take longer to respond
- CRM systems time out intermittently
- Carriers route inconsistently
- DNS behaves unpredictably
Nothing is fully down, but everything becomes unreliable.
And this is enough to disrupt the system if it is not designed for it.
This is why continuity is not about fixing dependencies in real time. It is about containing their failure.
If a dependency starts failing, the system should not collapse with it.
- Stop calling it when it is unhealthy
- Fall back to cached or minimal data
- Continue operating with reduced functionality
In contact centers, this shows up very clearly.
- If a CRM integration fails, routing should still continue. Screen pop can be delayed. Context can be reconstructed later.
- If an identity system is slow, agent workflows may degrade, but customer reachability should not be affected.
- If a carrier path is impaired, traffic should continue through alternate paths without requiring a manual switch.
This is the difference between a system that depends on its integrations, and a system that can operate without them for a period of time.
Continuity is an operational discipline, not a design feature
BCP does not fail because of architecture. It fails because it is not exercised.
The uncomfortable assumption in real incidents is this. The control plane may not be available when you need it.
If your recovery depends on logging into a console and making changes while the system is unstable, it is already too late.
This is why mature systems rely on static stability.
- Pre-provisioned capacity instead of last-minute scaling
- Minimal changes during incidents
- Traffic steering over reconfiguration
Failover is not about building new capacity. It is about using what is already in place.
And even then, not all failover is automatic.
In large-scale events, triggering failover is a decision. Acting too early or on partial signals can create worse outcomes than the failure itself.
This is why human judgment still exists in well-designed systems.
The Lie vs. The Truth (what customers are really testing)
| The Marketing Lie | The Architectural Truth |
|---|---|
| "100% seamless failover." | In real-time CCaaS, some in-flight interactions can drop in a severe event. A credible target is fast recovery for new interactions, with clear expectations on what is not preserved. |
| "Fully automated recovery." | Automation works well for contained failures, but large-scale or ambiguous events often require human judgment to avoid unsafe failover decisions. |
| "Backups guarantee DR." | Backups protect data integrity, not live continuity. Restoring takes time and may not be immediately usable across regions without prior design. |
If it isn't tested, it isn't real
Continuity plans that exist only on paper do not survive real incidents.
Mature systems are exercised regularly.
Not just for full outages, but for partial failures. Slow dependencies. Inconsistent state. Recovery under uncertainty.
The goal is not to prove the design works. It is to find where it breaks.
A simple question to ask any provider:
"What broke in your last drill that you did not expect, and what changed because of it?"
If there is no clear answer, the system has not been tested under real conditions.
The three questions that actually matter
- Who decides when failover happens, and why?
- What still works when the system is unstable, not down?
- What do you expect to lose, and is that acceptable to the business?
If these cannot be answered clearly, the architecture does not matter.