Demystifying AI: What It Is, What It Isn’t, and Why It Matters
This foundational post kicks off our AI Fundamentals series on
CXHACKS. We’ll explore what Artificial Intelligence actually means
in today’s world, the difference between narrow and general
intelligence, how machine learning works, and what it really takes
to become an AI-driven company. Whether you're a builder,
strategist, or just curious, this guide will help you separate
hype from substance.
Prasanna Arjunan• Dec 01, 2024 • 9:00 AM SGT
Distinguishing Intelligence: Task-Specific Tools vs. Human-Level
Ambition
The massive value AI delivers today comes primarily from
specialized systems—tools designed to perform
one well-defined task extremely well.
Think of:
An HVAC system that auto-adjusts airflow and temperature in
real time to optimize energy usage
An AI model that forecasts retail stock levels to minimize
overstock and spoilage
A computer vision system that detects parking violations from
surveillance feeds
These are examples of
narrow AI—high-performance, single-purpose
systems that solve specific problems with precision and speed.
In contrast,
Artificial General Intelligence (AGI)—AI with
broad cognitive abilities equivalent to human reasoning—remains
a long-term research goal. While generative tools like ChatGPT
may appear general, they are still bounded by their training
data and narrow instructions.
Researchers agree that AGI is still "very far away,"
likely decades or even centuries off, and will require multiple
breakthroughs across algorithms, reasoning, and grounding. The
rapid rise of generative AI has sometimes led to public
misunderstanding, with many assuming AGI is imminent. This
contributes to unnecessary fear and distraction from today’s
real, actionable AI capabilities.
The Core of Modern AI: Learning From Inputs and Outputs
Most practical AI systems today are powered by
machine learning, especially a technique called
supervised learning. In this approach, a model
learns to map known inputs (X) to known outputs (Y) by training
on labeled examples—essentially learning by example.
Here are some common input-to-output mappings:
Input: A video frame from a warehouse
camera Output: Detect whether a box is open,
damaged, or misaligned
Input: A short audio clip of a customer’s
voice message Output: Text transcription for a support
ticket
Input: A user’s purchase and search
history Output: Personalized product recommendations
A practical rule of thumb for evaluating whether supervised
learning can be applied is the
"quick mental judgment" principle: if a human can
perform the task in under a few seconds of thought, there's a
good chance it can be automated using supervised learning.
However, AI is not magic—it has limitations. It struggles with
tasks that require deep reasoning, abstract generalization, or
world knowledge. For instance:
Predicting minute-by-minute stock price movements based only
on historical data is unreliable
Inferring human emotions or intentions from short video clips
is extremely difficult
Handling inputs that are significantly different from training
data often results in failure
While AI can feel magical at times, it is ultimately pattern
recognition—not understanding. Knowing where it works (and where
it doesn’t) is key to deploying it effectively.
Deep Learning and Neural Networks: The Power Behind the Progress
Many of today’s biggest AI breakthroughs are driven by
deep learning, a class of machine learning
models commonly referred to as neural networks.
While the terms are often used interchangeably, “deep learning”
has become the more modern and popular label.
Despite being loosely inspired by the human brain, neural
networks are not biological. They are essentially
large mathematical systems made up of layers of
artificial “neurons” that transform inputs into outputs.
What makes them powerful is their ability to learn complex
patterns through layered computation. You don’t have to manually
define concepts like “affordability” or “risk score”—the network
discovers these internal representations on its own as long as
you provide:
Enough input data (A)
The correct corresponding output (B)
Deep learning models thrive when scaled. The more data you feed
them—and the larger the models become—the better their
performance, up to a point. This property has driven rapid
improvements in:
Speech recognition and transcription
Medical imaging and diagnostics
Real-time translation and language understanding
Personalized recommendations and ad targeting
The combination of massive datasets,
specialized hardware (like GPUs), and
modern training techniques has made deep
learning the powerhouse behind most cutting-edge AI systems
today.
The Fuel of AI — Clean, Relevant, and Strategic Data
Data is the lifeblood of modern AI systems. But simply having
large volumes of data doesn’t guarantee success. What matters
most is that the data is
relevant, labeled, and strategically acquired
to solve the right problems.
There are two primary types of data:
Structured data: Tabular information like
sales figures, timestamps, or customer segments—typically
stored in databases or spreadsheets
Unstructured data: Information that isn’t
organized in a table, such as images, video, audio, or
freeform text
Common methods of data acquisition include:
Manual labeling: Annotators tag data, such as
classifying whether a product review is positive or negative
Behavioral observation: Logging user
interactions, purchase history, click patterns, or sensor
readings
External sourcing: Acquiring public datasets
or partnering with vendors to access proprietary data
However, more data isn’t always better. Two common pitfalls
companies face are:
Premature data collection: Waiting years to
"build up data" before involving AI teams is a bad strategy.
Involving AI engineers early helps shape what data is actually
needed
Assuming all data is valuable: Just because
you’ve collected data doesn’t mean it aligns with your AI
goals or can be used effectively
Additionally, data is often messy. It may
contain missing values, inconsistencies, or incorrect labels. AI
models are highly sensitive to these issues and tend to perform
poorly when exposed to data that differs from their training
distribution. Data cleaning, augmentation, and validation are
critical steps in the development process.
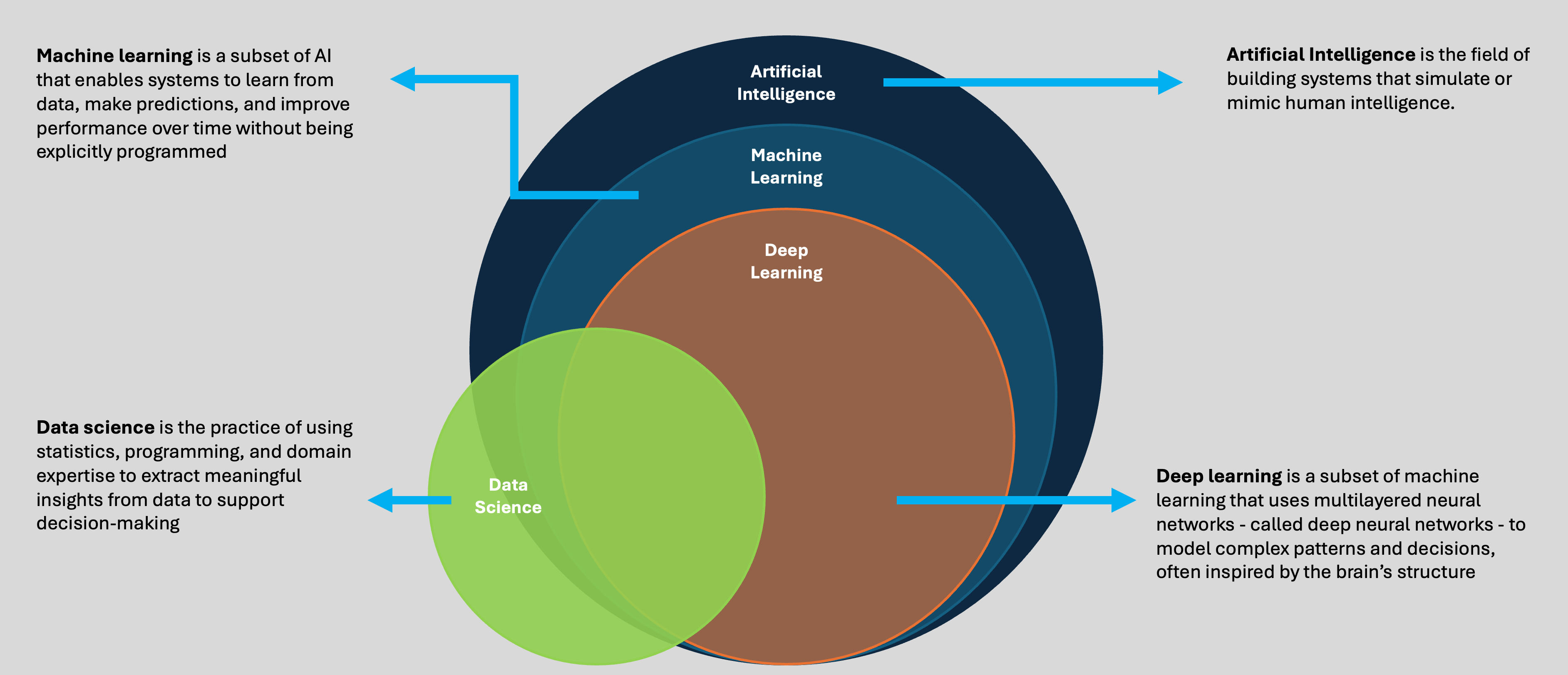
At this point, it helps to visually map out how these concepts
relate. The diagram below summarizes the relationship between
Artificial Intelligence, Machine Learning, Deep Learning, and Data
Science:
Visualizing the relationship between AI, ML, DL, and Data
Science
As shown above, Machine Learning is a subset of AI, Deep Learning
is a specialized subset of ML, and Data Science partially overlaps
with all three—focused primarily on extracting insights from data
rather than building automated systems.
Cultivating an AI-Centric Enterprise
Using a few models or deploying a chatbot does not make a
company an AI leader. True AI-centric organizations go beyond
tools—they redesign how they work to
maximize the unique advantages AI offers.
Key characteristics of AI-first companies include:
Strategic data acquisition: They
intentionally launch features or products to collect valuable
data, even if those features don’t drive direct revenue
Centralized data infrastructure: They invest
in unifying fragmented datasets into a shared, queryable data
warehouse that supports experimentation and insight
Automation-oriented thinking: They constantly
identify repeatable decisions or tasks that can be converted
into input-output predictions
New roles and team structures: They evolve
beyond traditional IT or analytics setups, introducing roles
like ML Engineers and integrating them into product delivery
teams
Becoming AI-first is not about magic—it’s about
system design and cultural shift. With the
right architecture, talent, and mindset, almost any large
organization can build meaningful AI capabilities over time.